Chris Padilla/Blog
My passion project! Posts spanning music, art, software, books, and more. Equal parts journal, sketchbook, mixtape, dev diary, and commonplace book.
- Finished Terry Pratchett: A Life With Footnotes - Rob Williams
- Still Reading Pyramids - Terry Pratchett
- Fellowship of The Ring is next! I've never read Tolkein's trilogy, should be fun!
- One off of Level by Disasterpeace. An oldie, but a goodie.
- Ape Escape OST. I've never played it, but it's a blast! 🐒
- Meditation Bells by Baldor and the Euclidean Functions. My current step-in for Chill Lo-fi beats to study to.
- 🏎 ティアーズ・オブ・ザ・スター by CASIOPEA. Such a journey. The guitar playing. 👌
- Ravel's Daphnis et Chloe ✨
- I'm rendering
CartItemFormwith React Testing Library - I'm simulating user interaction by selecting a spice level in the form.
- I'm clicking the submit button
- I'm asserting if handleSubmit has been called and if it has certain values.
- A passing test ✅
- More flexible, organized code ✅
- Bonus: I can more confidently refactor later, knowing I have tests in place 💯
- Testing allows for a clear explanation of what consumers of your code can expect. Rebekah says this is like documentation, but even better! Tests will actually verify that the code does what it says it will, unlike documentation.
- Testing allows you to write methodically. Writing the code is easy once you've written the expectations. This is further validation for testing as a process of clear thinking. Put another way: Measure twice, cut once.
- Testing old code illuminates tight coupling. Much of the talk is diving into an example of a long file of entangled responsibilities. Server requests, rendering data, managing state, all in one function. When you sit down to write a test for this, the coupling is quickly illuminated.
- I don't track this, but I'm confident my blog doesn't get a lot of traffic at the moment. :)
- I don't have keyword authority on Express or React, sure. But I have at least more authority with "Chris Padilla" in a tech context, I would think!
- I considered my URL structure. I don't keep any subdirectories, but I learned that this doesn't really have a large sway on SEO.
- Your site is large. Generally, on large sites it's more difficult to make sure that every page is linked by at least one other page on the site. As a result, it's more likely Googlebot might not discover some of your new pages.
- Your site is new and has few external links to it. Googlebot and other web crawlers crawl the web by following links from one page to another. As a result, Googlebot might not discover your pages if no other sites link to them.
<priority>: on a scale from 0 to 1.0, how important is this page? Landing page is 1.0. My music page is 0.9.<changefreq>: This site is alive! This is how to let bots know the interval it typically updates. My blog page would bedailyand my now page would bemonthly.- I know Wordpress has plugins for this sort of thing. But it's not really reasonable to migrate my site just for this sort of thing.
- TinyPNG is one of the plugins, and they have a CDN and API solution. They'll even save your images to S3 after optimizing. A bit too involved for my taste here, though.
- I used Sanity for AC: New Murder. They had a nice library for querying images in the exact dimensions you needed, and this could be done dynamically. Getting warmer, but I'm not in need of a full-blown CDN.
- Cloudinary has the same on-the-fly image optimizing through URL that Sanity has, and a very generous free tier.
- We don't need to test
fs, so I mocked that. getPostSlugsis essentially one level abovefs, so I mocked thisgetPostBySlugsimilarly is just a wrapper aroundfsafter being passed a slug, so I mocked that.- Allowing for an unhandled minor error being thrown in the console with
Cypress.on('uncaught:exception', ...) - Visiting the now page.
- Checking for a
.markdownelement. - Verifying it exists. If no result is found by
getLatestHap, a 404 would render. getLatestHapis grabbing a markdown file- My React component
NowPageis receiving the post - The page is rendering the result by creating a div with the class of
markdowninstead of a 404. - Age 16 — Dunkley Whippet
- Age 18 - Mobylette
- Age 20ish - Heinkel Trojan Bubble Car
- Age 22 - Morris Minor Van
- Age 40 - Lynn's Austin 1100
The Haps - March 2023
Valentines, Galentines, and Palentines! February was an A+ month! The grooves are tracked and I'm in them for code, music, art, and people.
Blogging & Dev
I'm getting the hand of this blogging daily thing! Lots of tech journals this month from learning testing in React.
Continuing on with the Tailwind redesigns at work! It's been coming along nicely. 👌 We'll be learning Docker at work, so I'm reading up on great quotes from Moby Dick. 🐳
I went to my first meetup in a while! React Dallas was a great hang. There's a really welcoming and smart community out here!
Music
I released Spring this month! I'm impatiently waiting for it to actually feel like Spring outside!!

Good things coming with guitar and piano! I'm learning finger style on guitar and am plugging away at reading jazz lead sheets on piano.
You can see what I've shared so far through the Music tag on my blog
Drawing

I'm getting close to finishing my second ever sketch book! I'm breaking the threshold of only learning from videos to actually learning through the craft. Like practicing an instrument, the training wheels are coming off and I can just start learning through practice. Exciting!
I'm still doing drawabox. Also going through the brand new Proko Drawing Basics course. Drawabox is so dense an zeroed in on construction that it's great to have a more general, exploratory curriculum with Proko.
You can see what I've made so far through the Art tag on my blog. I'm also sharing drawings on Instagram.
Words and Sounds
📚
🎧
Life
Early this month Miranda and I went to Denver, Colorado for The Gate. IYKYN, we both came back lit up and ready to rock and roll!
Tourist-wise, we got to see the Meow Wolf out there. We loved the original in Santa Fe when we went a couple of years ago. So crazy cool! Can't wait for the Grapevine location to open this summer!
We also saw Maggie Rogers. That concert was a blast! Great band, great crowd, great music.

👋
Louie Zong's Boss Rush & Sketches
Louie Zong's album Boss Rush and the CUSTOM BLENDER RENDERED 3D VIDEO is a gem.


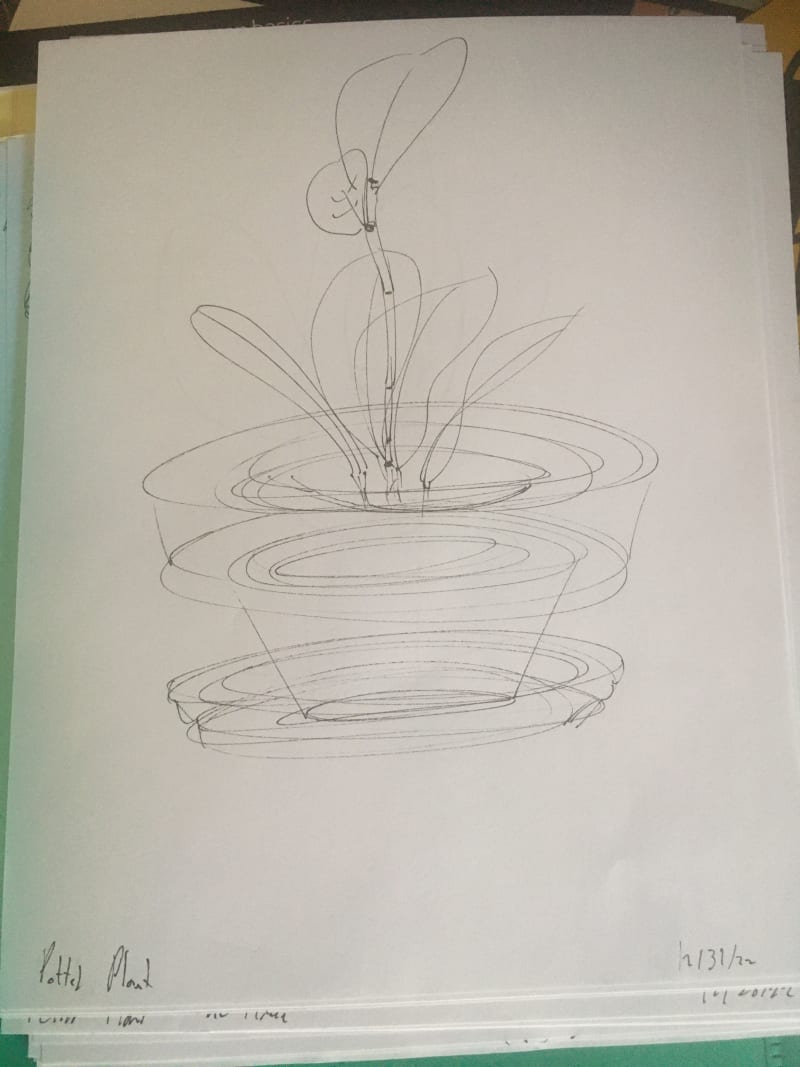
My last bit of plant construction for drawabox!
Faber — Grand Central Station
Big Rhapsody in Blue Vibes with this one. 🌆
Testing and Implementation Details
Redux casts it's vote for the methodology behind React Testing Library.
A key paradigm of React Testing Library is to avoid testing implementation details.
The reason being your users are namely concerned with the app behaving as they expect.
In react, that means not necessarily writing tests that your redux store is what you expect it to be. Instead, it's testing that information is rendering on the page correctly.
I can see the reason why. Implementation details change. Especially in modular systems. We should be able to swap redux out with a means of stage management without having to throw out or refactor our tests. That's twice the refactoring work when all we're concerned about is the app performing as it should be.
At the end of the day, that's more orthogonal.
Implementation Details Are Relative
My example from last time where I'm refactoring my form to elevate a handleSubmit method comes close to being overly concerned with implementation details. As a reminder, here's what that test looked like:
/**
* @jest-environment jsdom
*/
import React from 'react';
import * as reactRedux from 'react-redux';
import { render, cleanup, waitFor, fireEvent } from '@testing-library/react';
import CartItemForm from '../components/CartItemForm';
test('<CartItemForm />', async () => {
const rendered = render(
<CartItemForm
item={chipsAndGuac}
itemID={'5feb9e4a351036315ff4588a'}
/>
);
...
const spiceOptions = await rendered.findAllByTestId('option');
const firstOption = spiceOptions[0];
fireEvent.click(firstOption);
const addItemButtonElm = await rendered.findByTestId('add-item');
expect(addItemButtonElm.className.includes('selected'));
fireEvent.click(addItemButtonElm);
expect(handleSubmit).toBeCalledTimes(1);
expect(handleSubmit).toBeCalledWith(formExpectedValue);
}I would argue that this is not necessarily too concerned with implementation details, since the result from a form is a fairly important juncture in the flow of this app. AND I'm not really testing redux here. I'm simply verifying that our onSubmit is getting the information I expect.
However, this integration test is lower on the value scale compared to one where I'm also checking to see if the cart is rendering the correct data afterwards. And that is much closer to what the user is expecting.
Even so, I'm in the clear - if I swap dispatch for an external api, no big deal. I still want to verify that it's getting passed the information I expect. If we swapped the form for a different layout, that's another component entirely, and we wouldn't be able to avoid reworking tests in that case anyway.
A Higher Level of Abstraction
So that's one level of implementation details being disregarded. What about a level higher?
For this app, there's a higher level of abstraction. When it comes to properly updating an item in the cart, then it's important to pull further away from implementation details.
Here my logic is in the redux store, but I don't want to verify the values in the store. That's an implementation detail. I want to verify with what's rendering on the user's cart display is correct.
It's a surprisingly nuanced methodology. I can see why integration testing is a broad portion of the testing spectrum. An appropriate integration test from my last post would not be the same level of abstracted integration test as today's example. And I can see how it's a sweet spot in validating the security of your app. It's the most flexible type of test to give high levels of confidence in different applications and scenarios.
The Sweet Spot
I like to interpret that this is why the "integration part of Kent C. Dodd's testing trophy slopes. The higher up an integration is, the more likely that test will stick around as you swap implementation details, and the closer it is to what the user experience. Therefor, the more useful your test is as a tool for building confidence in the stability of your app.
In my mind, this doesn't negate the benefit of writing tests that are lower on the spectrum. Even unit testing, as a tool for writing modular code, is a pretty sound one.
But it checks out — integration tests sit in the sweet spot.
Testing Encourages Refactoring
I came across hard evidence that testing leads to well designed code this week. Taking the time to test old code is helping me decouple my JavaScript!
I'm using a NextJS E-commerce site as a playground for practicing writing tests. On the site, I have an item order page for each item on a menu. On the page, you can customize the item, select quantity, and then add them to your cart.
The component tree structure looks something like this:
<ItemDisplayPage>
<CartItemForm>
<CustomizationDisplay>
<AddItemToCart>
<ButtonWithPrice />
...ItemDisplayPage is the page level component, and ButtonWithPrice is the lowest child in this form. Everything else in between handles a spectrum of logic relating to the form.
The Rookie Mistake
This app is a 2-year old project, a portfolio piece written before I was full time in software. So there were some odd design choices.
This is the big one: My onSubmit function was in <ButtonWithPrice/>. Yikes!
const handleSubmit = (values) => {
dispatch({
type: 'ADD_TO_CART',
payload: {
...values,
},
});
router.push('/');
};It's doable because, with hooks and global state, I can make that call all the way from the button and it is technically possible.
That very much tightly couples my form logic with the submit button. The button should really only be concerned with rendering price, adjusting quantity, and then firing the handleSubmit method — NOT declaring it, though.
Testing Encourages Refactoring
At the time, it was no big deal. The app worked, tangled as it may have been!
When it came to testing the code, though, doing so was challenging.
I wanted to write an integration test the verifies that, on submit and after some interaction, I'm getting the right data saved to my Redux store. I want to do this from CartItemForm since that's a logical container for all of the interactions and form submission.
Here's a sketch of what that test looked like:
/**
* @jest-environment jsdom
*/
import React from 'react';
import * as reactRedux from 'react-redux';
import { render, cleanup, waitFor, fireEvent } from '@testing-library/react';
import CartItemForm from '../components/CartItemForm';
test('<CartItemForm />', async () => {
const rendered = render(
<CartItemForm
item={chipsAndGuac}
itemID={'5feb9e4a351036315ff4588a'}
/>
);
...
const spiceOptions = await rendered.findAllByTestId('option');
const firstOption = spiceOptions[0];
fireEvent.click(firstOption);
const addItemButtonElm = await rendered.findByTestId('add-item');
expect(addItemButtonElm.className.includes('selected'));
fireEvent.click(addItemButtonElm);
expect(handleSubmit).toBeCalledTimes(1);
expect(handleSubmit).toBeCalledWith(formExpectedValue);
}The gist:
With this test written, here's the problem - how do I mock handleSubmit and read the values? I simply can't with the way my component is structured!! I can't drill down and mock from this level. Even if I rendered my button component, the submit method is still within the component and not easily reachable. It has to be extracted in some way.
So, ultimately I moved the handleSubmit declaration up to ItemDisplayPage and prop drilled from there.
That allowed me to mock and pass the mocked handleSubmit method this way:
const handleSubmit = jest.fn();
const rendered = render(
<CartItemForm
item={chipsAndGuac}
itemID={'5feb9e4a351036315ff4588a'}
onSubmit={handleSubmit}
/>
);What do I have as a result now?
I can see why there are cultures around testing first. WHen using libraries that fall on the spectrum of being opinionated, it guides your code to being more resilient. The upfront cost of setup is paid off in the long run with easily changeable code.
Testing Organizes Code
Rebecca Murphey has a fantastic. talk on front end testing. It's all done in JQuery, and the principles still apply really nicely to react applications.
My favorite takeaways:
Jest Supports This Systematically
That last point is one I'm coming up against in my own codebase.
This site keeps all it's content in markdown. So I have a looong file with methods for grabing that data:
// api.js
const postsDirectory = join(process.cwd(), '_posts');
export function getPostSlugs() {
return fs.readdirSync(postsDirectory);
}
export function getPostBySlug(slug, fields = []) {
const realSlug = slug.replace(/\.md$/, '');
const fullPath = join(postsDirectory, `${realSlug}.md`);
if (!fs.existsSync(fullPath)) return false;
const fileContents = fs.readFileSync(fullPath, 'utf8');
const { data, content } = matter(fileContents);
const items = {};
// Ensure only the minimal needed data is exposed
fields.forEach((field) => {
if (field === 'slug') {
items[field] = realSlug;
}
if (field === 'content') {
items[field] = content;
}
if (typeof data[field] !== 'undefined') {
items[field] = data[field];
}
});
return items;
}
export function getAllPosts(fields = [], options = {}) {
const slugs = getPostSlugs();
let posts = slugs
.map((slug) => getPostBySlug(slug, fields))
// Filter false values (.DS_STORE)
.filter((post) => post)
// sort posts by date in descending order
.sort((post1, post2) => (post1.date > post2.date ? -1 : 1));
if (options.filter) {
posts = posts.filter(options.filter);
}
if (options.limit) {
posts = posts.slice(0, options.limit);
}
return posts;
}
. . .If I wanted to test getAllPosts, this is already difficult on a file-organization level. I can't very well mock the method getPostSlugs because with Jest you can only mock external packages.
I suppose this, in practice, isn't a terribly tight coupling. They are separate methods. But it has already illuminated an opportunity to break up this file to more closely follow a MVC model of organization. A strange paradigm to take on with the absence of a database here, but taking a step towards it lends to the first point at the top of this post - we get clarity in expectations of how this app is working. A big win already.
Generating a Sitemap in NextJS
I wanted to learn how to add search functionality to a NextJS Markdown blog. That's my blog and I'm starting to accumulate a lot of posts here! So I took to Google, and what did I find? Why, I found Julia Tan's post on "How To Add Search Functionality to a NextJS Markdown Blog".
I've been pretty happy with blogging being a more personal, long form means of keeping a dev journal. Recently, though, blogging has helped me find my people along the way. And that's really exciting!
When a Google search sent me to a personal site and not a Medium article or Stack Overflow forum, that got me pretty excited. I'm not looking to growth hack my blog or become a domain authority, but I do want to make it easier for folks to find these posts.
So begins an SEO cleanup!
The Current Situation
My site currently checks off the boxes for the bare bone necessities here: I have meta tags for pages and I'm using Semantic HTML for easy parsing.
I tried Googling a few of my own articles with some disappointing results. "Express React Chris Padilla" at the time brought up my landing page, but not my article on it.
I went through a few considerations of why this might be:
Sitemaps
No better source to ask about this than Google themselves. And a bit of looking brought me to sitemaps and why I might need one.
A Sitemap is largely what it sounds like: It's an XML file that outlines the pages on your site. Bots will use this to ensure all your pages are crawled. Here's mine.
Here's Google documentation on why you might need one:
"Large" to Google probably means hundreds or thousands of pages, but my page count is crawling day by day. More important is probably that this is a new site and I'm not breaking the internet with these posts.
Generating with NextJS
Next has great documentation on this and even provides code for generating your own sitemap.
I had to tweak mine just a bit to provide a couple of handy tags:
Here's what those tweaks look like in NextJS's generateSiteMap function:
function generateSiteMap(slugs) {
return `<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<!--Manual URL's-->
<url>
<loc>${BASE_URL}</loc>
<priority>1</priority>
<changefreq>daily</changefreq>
</url>
${slugs
.map((slug) => {
if (slug === 'blog') {
return `
<url>
<loc>${`${BASE_URL}/${slug}`}</loc>
<priority>0.9</priority>
<changefreq>daily</changefreq>
</url>
`;
} else if (slug === 'now' || slug === 'music') {
return `
<url>
<loc>${`${BASE_URL}/${slug}`}</loc>
<priority>0.9</priority>
<changefreq>monthly</changefreq>
</url>
`;
} else {
return `
<url>
<loc>${`${BASE_URL}/${slug}`}</loc>
</url>
`;
}
})
.join('')}
</urlset>
`;
}Getting those values is business as usual for NextJS: write a getServerSideProps method.
export async function getServerSideProps({ res }) {
// We make an API call to gather the URLs for our site
const pages = getAllPages();
const posts = getAllPosts(['slug']);
const albums = getAlbums();
const dynamicSlugs = [...albums, ...posts].map(
(contentObj) => contentObj.slug
);
const slugs = [...pages, ...dynamicSlugs];
// We generate the XML sitemap with the posts data
const sitemap = generateSiteMap(slugs);
res.setHeader('Content-Type', 'text/xml');
// we send the XML to the browser
res.write(sitemap);
res.end();
return {
props: {},
};
}Funny to me is that you still have to export a default function. The res.write() and res.end() method above handle sending the XML file. But, I suppose Next still needs to see a React component for this to work happily:
function SiteMap() {
// getServerSideProps will do the heavy lifting
}
export default SiteMap;And there you have it! Here's hoping you've reached the end of this article after searching "Generating a Sitemap in NextJS."
Blog to Find Your People
Austin Kleon shared Henrik Karlsson's "A blog post is a very long and complex search query to find fascinating people and make them route interesting stuff to your inbox." in one of his latest posts
A blog post is a search query. You write to find your tribe; you write so they will know what kind of fascinating things they should route to your inbox. If you follow common wisdom, you will cut exactly the things that will help you find these people. It is like the time someone told the composer Morton Feldman he should write for “the man in the street”. Feldman went over and looked out the window, and who did he see? Jackson Pollock.
...You will write essays that almost no one likes…. Luckily, almost no one multiplied by the entire population of the internet is plenty if you can only find them.
Kleon concludes that "This is really a great summary of the best thing that writing and sharing your work can do for you." Just as he outlines in moments through Show Your Work!
This is what drew me back to sharing online and firing up this blog. After reading Digital Minimalism by Cal Newport, I had taken on a Luddite's mentality to putting things out online. I swore to only doing in person socializing and purely offline means of communication.
It was great in many ways! Our brains are really wired for the physical connections of a dinner date or playing in a community band.
But the internet is such an amazing medium for connecting with kindred spirits.
From the Neopets forums to sending an email after reading someone's blog post, our work connects us. One of the best reasons to practice any art is that it's a form of communication with others in an elevated craft. That is amplified by making that connection with people beyond our local tribe.
Having a means of genuine connection with a global community. How rad is that?
This blog hasn't been going long, but I've already made some great friends just by saying hello and keeping up with each other's posts on our blogs.
Added bonus for blogging in particular - It's insulated from likes, from performance metrics, and it's a glove that fits the hand of the artist, vs cramming them into a box.
Romanticised? Maybe. But I think it's pretty darn special!
Chunky Head Construction
Studies and experiments on Andrew Loomis' Fun With a Pencil! Lots of chonky cheeks. 🙉

⚽️ Start here:
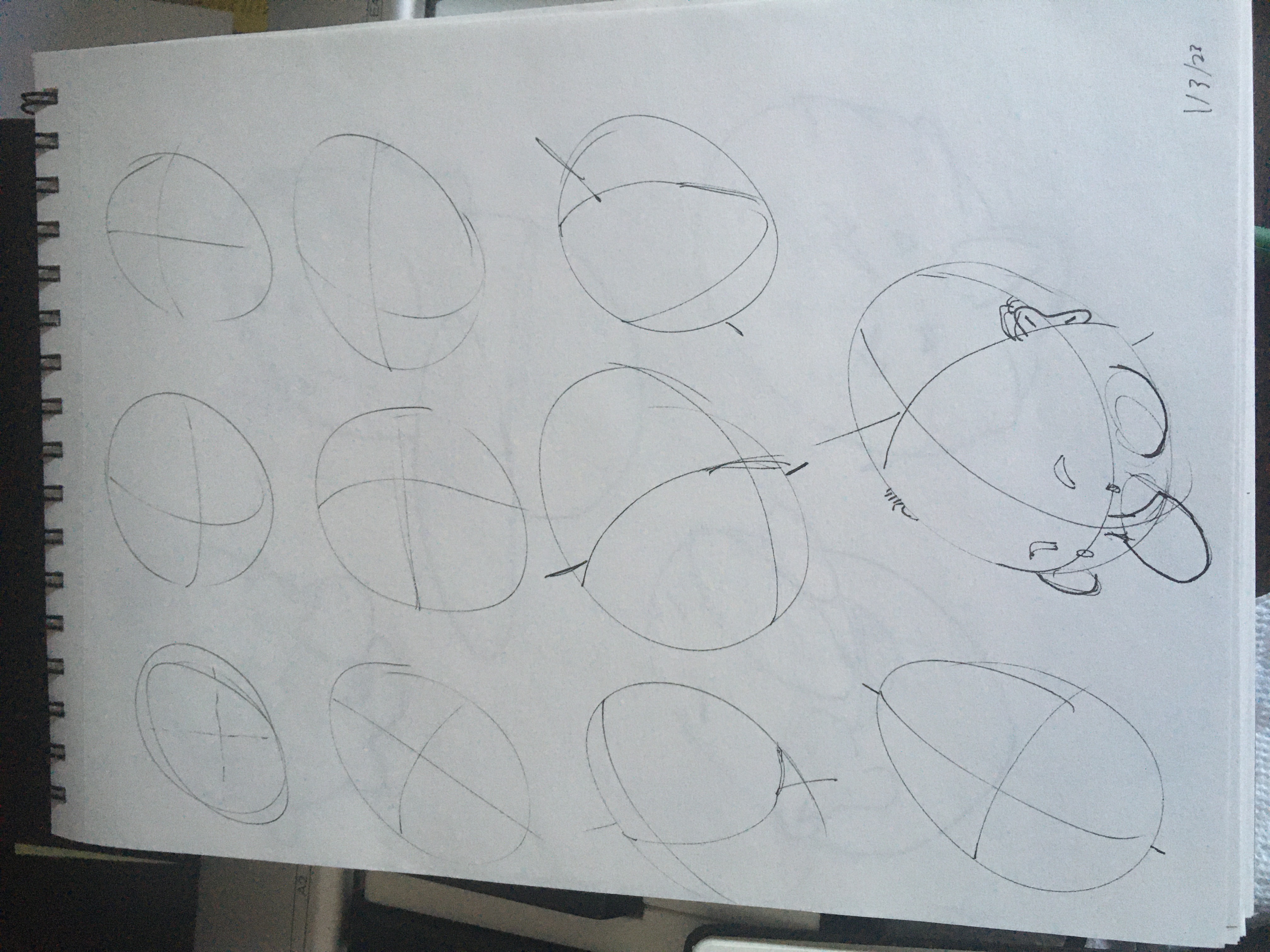
🙊 End up here:

Fingerstyle Prelude
Getting fancy with fingerstyle! 🖐
Hosting Images for chrisdpadilla dot com
My site is turning into a lot of images. I haven't really considered the way they're handled on my site very thoroughly until now.
My current strategy is hosting on an AWS S3 bucket and using the Image component from Next JS. With the component, Next handles the image optimization. So I can upload images as is (usually 2mb big) and Next will dynamically optimize for the resolution requested.
It's worked great on the pages I'm generating on the server. But I recently found out the component doesn't run on statically generated pages. For me that means all my blog posts aren't having their images compressed.
I serve up an RSS feed, and that approach won't quite do there either. The next component would be cumbersome while generating the feed.
Essentially, I need a non-Next solution for taking a moderately high quality image from my host and dynamically serving up a light-weight image.
My Options
So I'm turning to Cloudinary. And so far, so good! I've created a named transform so that all I have to do is add a t_optimize param to the url to get a resized, compressed image. I can get more granular with it from here, but for my needs, it feels like this gets me most of the way there to optimized images.
https://padilla-media.s3.amazonaws.com/albums/covers/spring.jpgAnd there we go! There's support to do this dynamically with JavaScript, and I have a way of bringing the images in to RSS without worrying about a heavy load time.
New Album — Spring ☀️

Keeping a Junk Drawer
I admit to being a notes nerd.
I keep most of my dev notes, blog ideas, To-Do lists, and research notes in plain text. I have neat little folders on my computer to keep them in place. I even use tags and record dates on my notes!
I day dream about implementing more organized systems like the Zettelkasten Method (as Idiscovered through the Draftsmen podcast) or using Wiki software (as advocated for by Andy Hunt in Pragmatic Thinking & Learning).
Those dreams usually crash on the reality of the non-linear and subject-hopping pattern my brain runs un.
Essentially - With notes, not EVERYTHING can be organized.
What helps keep a notes nerd like me at ease with this is an idea of a junk drawer.
Daniel Levitin in his book "The Organized Mind" closes the book with how our brains are naturally good at categorizing, and the "Miscellaneous" category totally counts as its own category.
This manifests in a few way for me: it's my hand-written, physical notepad where I write stream-of-conciouse-notes through the day.

I'm also starting most days with Julia Cameron's brain dump method of Morning Pages.
Even in my markdown system! I have a "Links.md" file where I grab links I might want later. If I notice a category is emerging, I can pull out a new markdown file and place them. But, for most things, it's just fine that I capture them and let them float down the river as I continue to add links.
date: 2023-01-18
url: https://www.youtube.com/watch?v=vUSWfeY7xAs&ab_channel=DrawlikeaSir
tags: art
notes: Resource for how to draw hands.
date: 2023-01-13
url: https://www.youtube.com/watch?v=JFg74x5bStg&ab_channel=PointLobo
tags: music, production
notes: Tips on creating music with a director. From Infinite Journeys, a CG animation project. Point Lobos is the artist. My favorite tips are 1. Record midis before recording actual tracks when possible. and 2. Don't get emotionally attached to your music. Be ready to chop it up. It becomes a new piece.
date: 2023-01-13
url: https://blog.jim-nielsen.com/2019/i-love-rss/
tags: tech
notes: Jim Nielsen's Favorite blogsEven with music writing - I have an improvisatory, molecular ideas folder. "Cool baseline.mp3", "Pretty Piano Flourish.mp3". And then from there, some of those get pulled into fleshed out songs.
The junk drawer keeps me loose in the same way gesture drawing does. It keeps me quick to jot something down, with no judgement of the process in the same way I would be if I were writing in a blog CRM or a tweet.
What Over-Mocking Looks Like
TIL!
I'm testing a method that grabs the latest post tagged with "Hap." I want to verify that the post will return the latest result.
import fs from 'fs';
import { getLatestHap } from '../lib/api';
jest.mock('fs');
jest.mock('../lib/markdownAccess', () => ({
getPostBySlug: () => ({ slug: '2023-01', tags: ['Notes', 'Haps'] }),
getPostSlugs: () => ['2023-01'],
}));
test('getLatestHap', () => {
const sampleMarkdownFile = { slug: '2023-01', tags: ['Notes', 'Haps'] };
fs.readdirSync.mockResolvedValue([
'postone.md',
'posttwo.md',
'postthree.md',
]);
const result = getLatestHap();
expect(result).toStrictEqual(sampleMarkdownFile);
});I had to mock a few things to abstract their use:
So there! I've mocked all that doesn't need testing.
I then realized... what's left for me to test here?
This is the function I'm testing:
export const getLatestHap = (fields = ['slug', 'tags']) => {
const posts = getAllPosts(fields);
const latestHap = posts.find((post) => post.tags.includes('Haps'));
return latestHap;
};I've mocked this to the point where I'm essentially testing the native find Array method. Whoops.
Mostly Integration
This is me learning from experience what Guillermo Rauch tweeted and what Kent C. Dodds expands upon:
Write tests. Not too many. Mostly integration.
Here I've nailed the first one, started to drift from the second point, and need to move towards the third to make my way out.
This test is trite because it's not testing any logic. This would largely be better as an integration test, or perhaps even an E2E test in Cypress. In an E2E test, I would be grabbing lots of different cases along the way - are my pages loading, is data coming in properly from the source, and does it ultimately render correctly.
I've been learning about Jest, so this is a case of "Every problem is a nail when you have a hammer."
Ah well, lesson learned!
E2E Version: A better way
Here's what that test looks like in Cypress:
import { BASE_URL, BASE_URL_DEV } from '../../lib/constants';
const baseUrl = process.env.NODE_ENV === 'production' ? BASE_URL : BASE_URL_DEV;
Cypress.on('uncaught:exception', (err, runnable) => {
return false;
});
describe('Verify Now Page Renders Blog Page', () => {
const blogURL = `${baseUrl}/now`;
it('Loads the blog page with post', () => {
cy.visit(blogURL);
const markdownContainerElm = cy.get('.markdown');
markdownContainerElm.should('be.visible');
});
});Here's what I'm doing:
Same amount of code, but here's what was tested along the way:
That's way better mileage over my trite unit test from before!
Vehicles as Eras of Life
I'm still enjoying Terry Pratchett's Biography.
One of my favorite things about it so far is that, amidst all the interesting life stories, milestones, new jobs, new places lived, the characters Terry came across — with all that to talk about, there's still a non-trivial number of words dedicated to talking about the different cars and bikes Terry drove around.
It's one of my first biographies that I'm giving a read, so maybe this is normal? Maybe I skimmed those parts of Will Smith's Biography? Does the Steve Jobs Biography lament that he never made it to driving a Tesla?
I'm only partway through, but I don't think Terry was a motor buff, so that's not why, right?
It's funny to me — but it's relatable. It's a shared experience — those fond memories of "The 100k miles+ hand me down I took to college" or "The Toyota we shared while we saved up money to make it through grad school."
Some folks can mark major periods of their entire lives with their vehicles.
Here's Terry's timeline so far as I've read, ages estimated by context:
On a related note, I bought a new phone the other day. I have to admit, though, it doesn't have the same "The start of a new era" effect that cars do.