Chris Padilla/Blog
My passion project! Posts spanning music, art, software, books, and more. Equal parts journal, sketchbook, mixtape, dev diary, and commonplace book.
- Never Meant
- Dawn from Pride & Prejudice (2005)
- Weird Fishes/Arpeggi
- North Central Texas Winds
- I'm Old Fashioned
- The Sound Design of Pedestrian Call Buttons
- Tending the Garden With Tag Pages
- Software Without Scale
- Two Chords
- Compass
- Three Years of Blogging
- Critical Thinking and Coding Agents
- Extending Functionality Through the JS Proxy Class
- Handling Errors in LangGraph (and Other State Machines)
- Full Page Video Across Devices with React
- Testing Time Interval Code
- What It Is by Lynda Barry
- So Many Books by Gabriel Zaid
- Art & Fear by David Bayles & Ted Orland
- Sam & Max: Surfin' the Highwa by Steve Purcell
- Robin Sloan's Blog on media & technology
- Austin Kleon
- Matt Webb's Interconnected
- Melon King
- LGR
- Soft Skills Engineering
- Artvee
- Moving to Boulder 🏔️
- Revisiting a childhood hobby ⚡️
- Fun trip to Miami for work 🦩
- Enjoying being engaged 💍
- Home in Houston for the holidays 🎄
- Several good movies seen. Harry Potter in theaters, It's A Wonderful Life also on The Silver Screen, Good Will Hunting, Hamnet, KPop Demon Hunters, Whiplash 🎥
- Earlier this year, after using inline suggestions for some time, the jump to prompting an agent that then writes multiple files' worth of code was shocking! The feeling of it running away conjured images from the Sorcerer's Apprentice.
- Returning to the approach several months later, trying it in my own projects, the results were suddenly thrilling! With the right wrangling, what was previously tedious to implement became trivial. The possibility of accelerated speed was intoxicating.
- The Music of Raymond Scott, composer of the tune Powerhouse, of Warner Bros. cartoons fame.
- Pink Champagne: A Collection of Vintage Light Music, perhaps our closest replacement for the Ren & Stimpy Production Music collection.
- Music To Knit By, humorously reminding me that the themed music streaming playlists are part of a long tradition of pragmatically curated music. Another era's Lofi Hop Hop Beats To Relax/Study To!
- Music by Candlelight at Teogra, classical guitarist & violinist provide easy listening to diners of the titular restaurant, recorded for your listening pleasure.
- Get back to pencil-and-paper after a deep dive into fully digital
- Lean into figure drawing
Little Mountain Park

There's this park near our new place that has these miniature mountains for the dogs to climb. Lucy loves them!
Open Source 1998
The change in spirit of the web and even open source itself is well encapsulated in a comparison between the 1998 version and the 2026 version of opensource.org. One dressed up and attending galas, and one handing out zines.
Perhaps one of the primary reasons for its success over the free software movement is in the marketing. From the Case for Open Source: Hacker's Version:
Mainstream corporate CEOs and CTOs will never buy 'free software', manifestos and clenched fists and all. But if we take the very same tradition, the same people, and the same free-software licenses and change the label to 'open source' - that, they'll buy.
One of the chief objections to using open source and free software during this time was around reliability. The case is made by Eric S. Raymond on the '98 page with a very period-appropriate angle:
Of all these benefits, the most fundamental is increased reliability. And if that's too abstract for you, you should think about how closed sources make the Year 2000 problem worse and why they might very well kill your business.
The several other case pages are fun to flip through since, of course, as it turns out, Eric was right.
2025

I'm very clearly a naturally reflective person. So I won't miss the opportunity this year to take stock of what was a very big year personally.
My intent from last year was to chop wood and carry water. Mission accomplished.

Creative Work
A couple of major projects! Bird Box is the biggest one. It was a blast making something that used a wide spectrum of the mediums I work in, all for one project.
Amethyst is still something I'm very proud of. A convergence of love for Drum and Bass, early CG, and the feeling of being drawn into a world, a la Myst.
Only one other non-project album, Goose Creek. Unless you count the whole moving out of state part. That was, indeed, a project!
More of a technical accomplishment, but it feels like home here now that I have music playing on this site.
Music
Proprioception!! I had a great breakthrough with being able to play piano with my eyes on the music and away from my hands this year. A huge accomplishment, and one that will accelerate my piano playing from here on out. It's breathed new life into playing as well. That feeling of soaring is there!
I gave a valiant effort for chord melody early this year, to then switch my focus over to Math Rock and Midwest Emo. Hoping to return to chord melody another time, with more chops and speed across the fretboard. Learning short licks, though, has been an energizing process. The quick loop of practicing and recording has been a great engine this year.
Listen to more music.

Art
In some ways a slower year, but a more interesting one. Gaining some fluency in Blender was a fascinating endeavor.
Much of my work has been beneath the surface here. My sketchbooks are fuller, and I've worked my way through a few more courses and books. This is one of those hard-to-quantify improvements from the year. Ultimately, I'm thrilled with the progress.
Summaries here:
Favorite pieces:
See more art.
Writing
Feels free and flowing. A big barrier to getting words on the site came from the feeling that I always had to make these thoughtful, polished posts. Not every piece required that, so I've leaned into Clippings and a Links Feed. The site feels more like a notebook in that sense, now, which helps with keeping me engaged openly with it.
Favorites:
Read more notes from the blog.
Software
Wild year for software. I have a few AI agents I've developed out in the wild now. And AI moved from being an occasionally helpful autocomplete to an entirely new way of accomplishing work. I'm still learning how to continue to best integrate AI-assisted coding into my workflow. But it has been quite the game-changer.
See more from the tech blog.
Reading
My reading hasn't been as prolific as years past, but what I did pick up, I thoroughly enjoyed. If I had to pick favorites:
See more on the bookshelf.
Web
A few websites, blogs, and creators I've truly enjoyed this year:
See more on my links page.
The Hard To Capture Bits
Lots of life happened this year:
2026 Intention
New projects and habits take a certain level of rocket fuel to break the atmosphere before coasting, reaching the chop wood, carry water phase. Several atmospheres have been broken for the past several years in my world. I have one more big one on the horizon in the coming years. So my intention for this year, somewhat similar to last year, is to simply keep going. Albeit — with a greater focus on "roots" as I've been putting it to Miranda. More foundational studies, more etude practicing, more learning around what doesn't change in software.
One other added twist: taking time to enjoy what's been accomplished so far. I have a tendency to always be pushing, learning, growing. What I find at year-end, when there's time to slow down and reflect, is that new things are born from a slow pace. This year would be a great one to dial back a few of the extracurricular practices above. Leaving room for what's next.
I doubt I'll be able to fully pull back. There's still more to learn, do, and accomplish this coming year. But, there are also many memories to make IRL, more play to have in the practices, and more daydreaming to do for the next chapter.
Happy New Year!
O Come, All Ye Faithful
Merry Christmas, everyone! ❄️
Album Player On Site!

It didn't feel very POSSE of me to have so much on this site as a source of truth, except for my own albums!
All the major players have their baggage in the music hosting/streaming space, unfortunately. Even previously humble Bandcamp has traded parent companies twice in the past few years.
And besides — I have to say there's a little something special in having music play on this lil' site — in the same way that a hand rolled pizza at home is different from a frozen one, eh?
So I whipped a solution up this morning! See an example on the ol' Bird Box OST page.
Tech
For the technically curious —
The base html audio element, like so many others, comes out of the box with plenty of helpful attributes. There's some extra work to get a playlist style interface, but this is handled through those attributes. Namely: onEnded, which allows the player to continue to the next track, onTimeUpdate to visually show track place, and onLoadedMetadata for keeping tabs on the track length (helpful for visual slider for track time position)
const PlaylistPlayer = ({ tracks }) => {
const [currentIndex, setCurrentIndex] = useState(null);
const [isPlaying, setIsPlaying] = useState(false);
const [currentTime, setCurrentTime] = useState(0);
const [duration, setDuration] = useState(0);
const audioRef = useRef(null);
const handleTimeUpdate = () => {
setCurrentTime(audioRef.current.currentTime);
};
const handleLoadedMetadata = () => {
setDuration(audioRef.current.duration);
};
const handleEnded = () => {
if (currentIndex < tracks.length - 1) {
play(currentIndex + 1);
} else {
setIsPlaying(false);
}
};
// . . .
// part of the return:
<audio
ref={audioRef}
onEnded={handleEnded}
onTimeUpdate={handleTimeUpdate}
onLoadedMetadata={handleLoadedMetadata}
/>;
};
export default PlaylistPlayer;Funnily enough, the range input element works well for showing and adjusting the track position:
const handleSeek = (e) => {
const time = parseFloat(e.target.value);
audioRef.current.currentTime = time;
setCurrentTime(time);
};
// . . .
<input
type="range"
min={0}
max={duration || 0}
value={currentTime}
onChange={handleSeek}
aria-label="Seek"
/>;The rest is styling and a few more handlers in the React component.
Files are stored on AWS through S3. I had to whip up a script to upload and adjust my albums.js file en masse, a somewhat tedious task since many older albums were not quite as organized as my newer ones. Left plenty of time to get nostalgic!
Give it a whirl! Visit any of the albums on my music page.
Painting Studies

A series of studies done as part of Jeremy Vickery's Painting Light course.
One fellow student left a note saying that the course felt a little like the draw the owl meme. There's some truth to that — for the most part, Jeremy is providing a set of photos, telling you what sort of aspects of light to look for, and then having you take a jab at it on your own.
I was having this conversation recently where I shared that, looking back, great teachers do a lot for their students. But I think the benefit many people are really looking for is permission to do a project, and holding a container for doing the work. On the surface, that's a low bar. In practice, though, it's highly valuable and not so simple to do.

The drop into the deep end of observation is part of the strength here. By starting in observation, it's possible to paint anything you see. From there, then technique, construction, lighting principles, etc. can help streamline that process and lend to further creation from imagination.
The biggest "Aha" for me was in the images above and below. Both highly reflective material, I assumed they were advanced subjects. At the end of the day, though, once you sit down and really observe what you're seeing, there's not much more you need to know or do. You simply draw whatever truth is in front of you.

More to do next year in the course! Excited to keep going. I've also added this to my handy-dandy page of learning resources.
How to Draw the Tick

While I understand the actual frustration that this and similar jokes jab at (there are plenty of examples of poor instruction out there), there does come a point where a teacher, book, tutorial, has to let go of the student's hand. You just have to... draw the Tick.
Claude Code Sound Effects
A riff on Claude Code Muzak. Using the same hooks interface to play a system sound on task completion and when asking a follow-up question. Simply add this to your .claude/settings.json:
{
"hooks": {
"Stop": [
{
"hooks": [
{
"type": "command",
"command": "afplay /System/Library/Sounds/Hero.aiff"
}
]
}
],
"PermissionRequest": [
{
"hooks": [
{
"type": "command",
"command": "afplay /System/Library/Sounds/Funk.aiff"
}
]
}
]
},
}🔔
Critical Thinking and Coding Agents

I've gone the Agentic-AI coding way for the past couple of months. My initial responses to it may mirror your own:
Depending on your bent towards pessimism and optimism, the order of events may be different for you. Programmers, as those who now largely work with AI closely in our daily work, have been getting a very pragmatic understanding of the tool as it's emerging, finding its edges and where it can improve our work. So, naturally, consensus is between the two extremes of rejection and hype. This is a powerful tool, and it takes a separate skill to fully understand where it's appropriate to use and how to get the results you're looking for. Here are some thoughts on navigating the middle path:
Vibe Coding Vs. AI Assisted Coding
It's worth knowing the difference. Similar to how there is a spectrum between scenarios where you are comfortable using a package and scenarios where your team develops your own solution for a problem, there's a range between letting the coding agent have free rein and integrating with that process heavily.
Birgitta Böckeler has a great exploration outlining formally what is really an intuitive process. Prototypes, proof-of-concept, and throw-away code are an easy choice for letting the agent take the wheel. Anything beyond that takes a consideration of the tradeoffs between speed, quality, and cost. (Cost, interestingly, is spread across a few different currencies here: Cost of context in your agent, cost of mental resources you have available, cost of digging through the docs, etc.) For most daily work, debugging and producing production-level code, you'll learn best how to integrate it as part of your process instead of a replacement.
Engaging Critical Thinking
While still in the early days of mass access to integrated LLM usage, we're seeing that the tool is overly eager to be useful. Responses to user queries from the major AI players are long-winded. Coding agents aim for verbose solutions. And speed is the preferred default over what we're now seeing in "reasoning" or "thinking" modes.
The speed and length are somewhat alluring. While getting familiar with these tools, it's easy to pass over much of the reasoning to the tool, but we have to be careful there.
There are a few studies already underscoring the hypothesis that we are thinking less when using these AI tools. You can find them in Maggie Appleton's A Treatise on AI Chatbots Undermining the Enlightenment. There you'll also find a compelling solution to this issue through your own prompt engineering. If the AI tool tends towards flattery and confirmation, tell it to do otherwise.
So our aim is clearly for deep involvement in the process while using these tools, but we have to be mindful that the tool itself may not be working in that interest out of the box. Restraint, practice, and perhaps a different framework of interacting with the agents are required.

The Chat Interface
I think this is also partly due to the UI here.
Agents, be they general-user-facing or, now, IDE integrations, are engaged with through a chat interface. Think of where else this interface exists: Discord, Slack, your favorite social media's direct messages, sms text clients, those finicky chat bubbles on portfolio websites, and, for old-time's sake, AOL Instant Messenger.
You get the idea — these are not interfaces for writing prose, editing and refining a document, and going at a steady pace. This is a space for quick responses and moving the conversation forward. Even the ping-pong of question and answer implies that we should move on with haste.
For a technology whose domain language is... language! It certainly is intuitive. However, for software development in particular, we need to ensure the tool is not so over-eager to spin out the solution that we are then racing to keep up. A thoughtful UI can help encourage this.
Superpowers and Spec Driven Development
Much of this is to say that my sweet spot for AI-assisted coding has been with the aid of a couple of different tools that help mitigate the major concerns above.
For a broad exploration of what's out there in the Spec Driven Development space, Birgitta Bockeler returns with a thoughtful article here.
My favorite at the time of writing has been Superpowers by Jesse Vincent. The technology underneath this is not overly complex: The heart of it is a series of prompts that you can read on the GitHub page.
The framework encourages you to work in phases: First, brainstorming high-level considerations and edge cases, then writing an implementation plan with code samples, and then implementing the plan sequentially with quality checks along the way. A massive improvement in thoroughness from even Claude Code's planning mode alone.
Even better is that markdown files are generated as artifacts along the way. This serves a couple of different purposes: You can limit the context provided to an agent, externalizing it from the current agent's memory and allowing you to spin up another agent to handle the next phase. And, from a user standpoint, we then have the opportunity to step away from the chat interface and thoroughly review the plan thoughtfully.
As an aside — the markdown files are, largely, disposable. Perhaps part of the idea of having these files written is that they can then serve as reference documentation down the line. Unfortunately, change happens quickly, and it then becomes an issue of keeping multiple documents in sync. So, thus far, I've tossed these files after a given phase of a feature is complete.
The primary benefit in my own use is that any feature of medium complexity is now something that I have the chance to think through thoroughly, from high-level design to implementation details, all while also appreciating the benefit of a tool that can type much faster than I can.
Raising Our Gaze
We are still in the wild west. Practices are continuing to evolve. For medium-sized features, Superpowers, along with similar frameworks, are aiding in ensuring that we are using the tools and not the other way around.
Our role is to continue to be the primary holder of context: Only you fully understand the full logistical needs of the project, what sort of tradeoffs you want to make, and the long-term infrastructure work that will keep your application continually extendable.
With that intent in mind, I optimistically see a novel way of development emerging. Another layer of abstraction is being built, where we can continue to move our gaze a bit further from syntax and tedium, and focus on the design aspects of our work that truly matter.
Elephant Gym – Finger
AI Agent Elevator Music

Matt Webb shares via Interconnected Mike Davidson's Claude Muzak:
I suggested last week that Claude Code needs elevator music…
Like, in the 3 minutes while you’re waiting for your coding agent to write your code, and meanwhile you’re gazing out the window and contemplating the mysteries of life, or your gas bill, maybe some gentle muzak could pass the time?
Delightful.
A few tracks are already provided, you'll have to bring your own audio files for more varied listening. Music For Local Forecast. Or perhaps anything Vaporwave! And all sorts of library music comes to mind.
For more whimsy, 1950's era incidental music would also be a terrific fit. Eons ago in internet years, there was a great collection of public domain light music tracks that were used for Ren & Stimpy, but download links are no longer handy.
A few finds from the internet archive that should fit the bill:
As a technical aside, this is a very slick use of Claude Code hooks. Common productive examples could be cleanup scripts, including a rules.md with your prompt, applying code formatting, etc. Nice to see such a fun use!
// .claude/settings.json
{
"UserPromptSubmit": [
{
"hooks": [
{
"type": "command",
"command": "python3.11 /Claude-Muzak/claude_muzak.py hook start"
}
]
}
],
"Stop": [
{
"hooks": [
{
"type": "command",
"command": "python3.11 /Claude-Muzak/claude_muzak.py hook stop"
}
]
}
]
}Learning Resources & Bookshelf Pages

Very excited to share what aims to be helpful guide for like-hearted creative folks: A bookshelf page and a learning resources page on this site!
My bookshelf has existed on the site for a while, but is now in a fully fleshed out state with all books previously mentioned on the blog in attendance.
I'm most thrilled for my Learning Resources page! Spanning frequent domains on the blog: art, music, software, creativity. There are dozens of entries across books and online material. Some paid, but plenty free as well.
Naturally, both will grow organically over time as I give trial to more material.
I owe a great deal to the folks who have been generous with their books and resources online. Switching into software was a winding road that began with Derek Sivers' book notes. My initial education in software was structured thanks to the thoughtful curation of articles and courses linked through The Odin Project. And the initial map for my art education was borrowed from a generous list by Noah Bradley. The list goes on.
This blog has partly been an attempt to give back as much as I can. With posts spread across several pages, dates, and subjects, it was time to wrap them up with a bow some of my favorites for learning art, music, programming, and living creatively!
If any of these subjects are your medium, I'm hoping there will be some entries that are new to you, and some that will be familiar — casting another vote for the material.
Enjoy!
Gulfer – Heat Wave
Figuring Out Figure Drawing

It's been a couple of years since sharing a peek inside a completed sketchbook.
This one was very targeted in a couple of ways on my part:
I spent a great deal of time with Mike Mattesi's Drawing Force book and web course. I have more to do and learn, but several things started to click during these past few months of focused study!

I pass on the course and books to you with high recommendation. When I first took a stab at the books and the course, I was convinced it was too advanced to be a beginners course. But now I recognize something in the approach that I had done as a teacher myself: planting the seeds for appeal and gesture early (in the case of music: tone and phrasing). It could be saved for later, after the fundamentals are thoroughly set. But why wait? Let compound interest work it's magic.
The style of the Force method is very fluid and alive. It takes wrangling, but it's much more engaging than the more measurement-based approach of pure observational drawing. Like getting at the heart of a piece of music rather than reading notes on the page alone.
Though, I probably spent more time being sure I was seeing the model and staying true to their form. Quite the tricky balance: pushing gesture while capturing essence. I suppose it's not a matter of either/or.
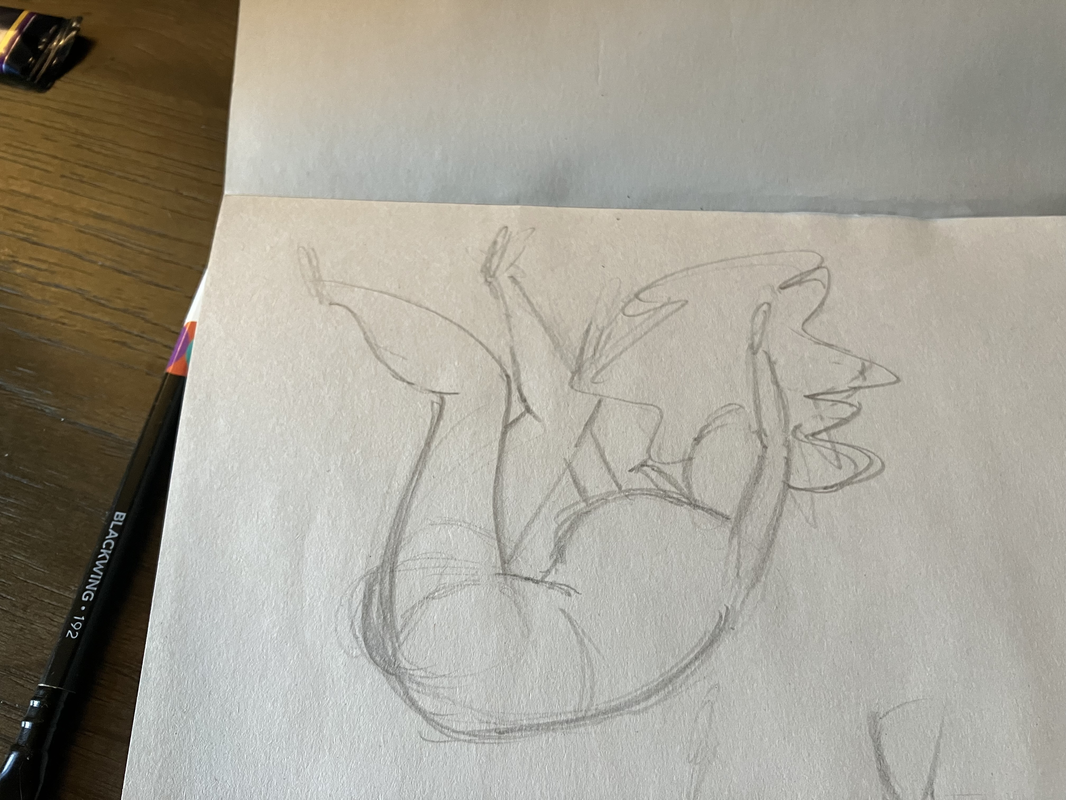
Something that's hard to express through the images alone — it was supremely fun to do! The immediacy, the focus on the energy around expressing the gesture of a pose, and the embodied experience of carving out those rhythms from the figure.
There's simply something to having a sketch on paper sitting on a desk as well. Unmistakably there, holdable in your hands, textured from the material and etchings of the pencil. Am I too romantic about it?
My favorite benefit from spending ample time in a cheap stack of newsprint is how disposable and unprecious it is. Bad drawing? Next page. No Ctrl-Z or glowing screen that urges for polish and perfection. I do love doing digital work. And still, it's nice to take a breather and really let loose on the page.
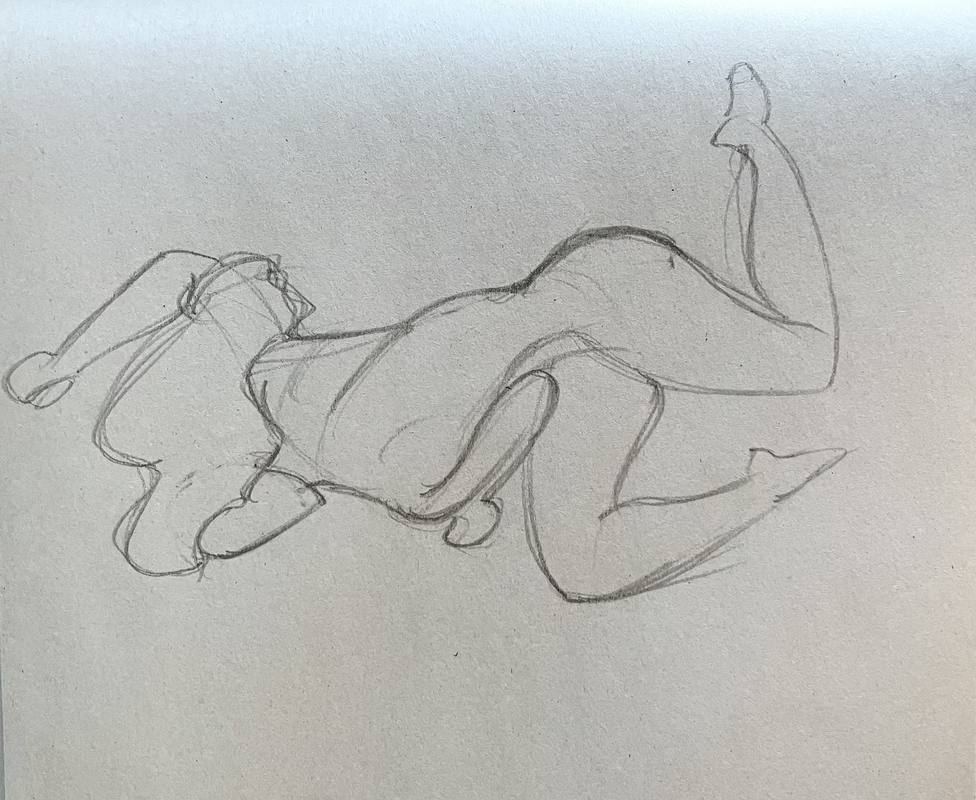
I still catch myself being surprised that the real skill of art is being able to see. The answer is in plain sight. The muscle that develops is the patience to see more and the pattern matching to capture ideas more quickly.
Onward, to deeper seeing!

Clementi – Sonatina, Op. 36 No. 1 Mvmt. III
A huge milestone in developing proprioception! One of a handful of pieces performed with eyes off the hands and on the sheet music. You can hear me "sounding-out" the next few syllables when a sizable leap is involved. But! All around not too shabby. Progress!