Verify Site Links with Cypress
Here I'm continuing to flesh out my Cypress tests. I've had a few blog pages that have been pushed live, but turn up as 404's due to a formatting issue.
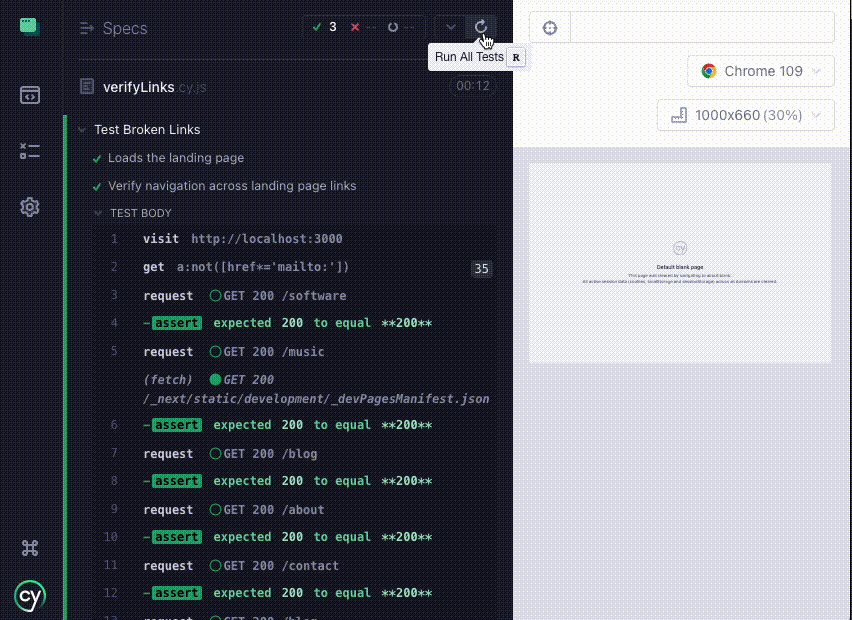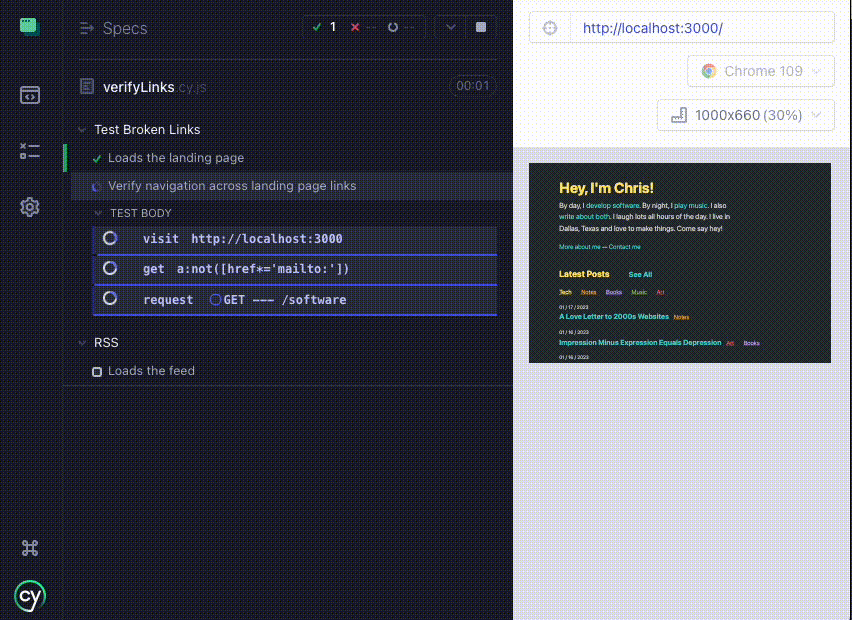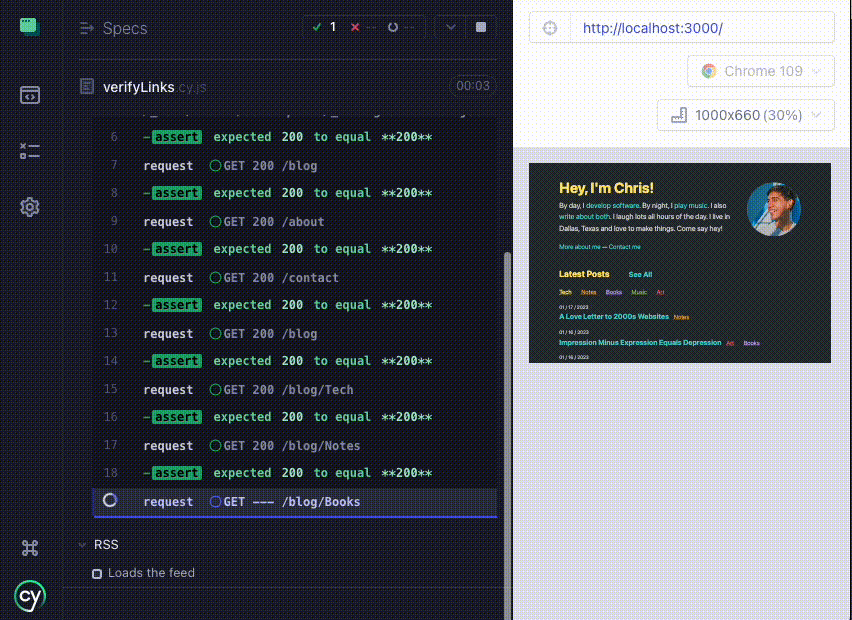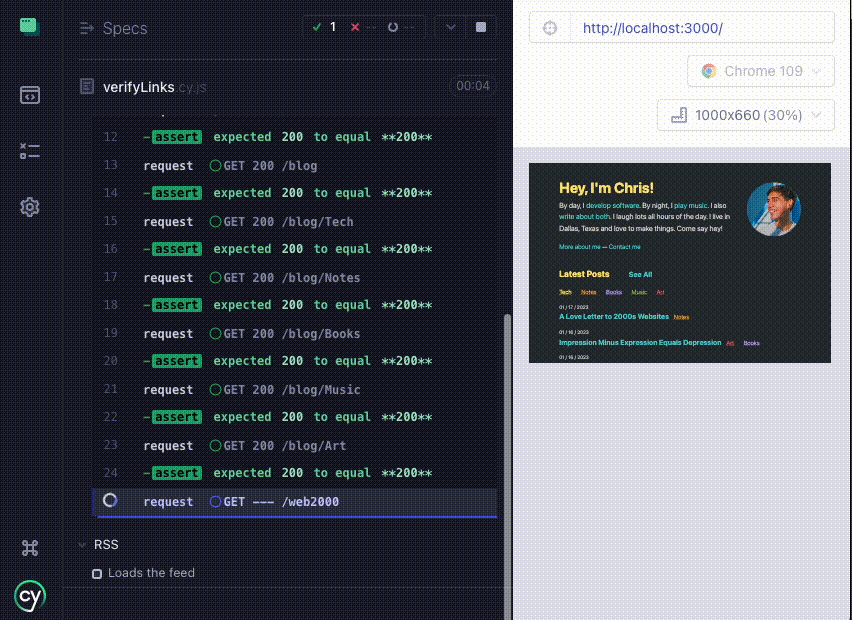
Here, I'm writing a script to verify that all the links on my main page, including blog links, all return a 200 status code.
Writing the Test
Here's the code from last time verifying my RSS Feed:
describe('RSS', () => {
it('Loads the feed', () => {
cy.request(`${baseUrl}/api/feed`).then((res) => {
expect(res.status).to.eq(200);
});
});
});I'm going to continue to use res.status to verify a 200 response. It's simpler than loading up the page.
To run this, I'll need to:
- Load the landing page
- Get all non-mailto links
- Verify each of those links
- Along the way, exclude any edge cases.
Here it is in action:
import { BASE_URL, BASE_URL_DEV } from '../../lib/constants';
const baseUrl = process.env.NODE_ENV === 'production' ? BASE_URL : BASE_URL_DEV;
const excludedLinks = ['bandcamp', 'linkedin', 'instagram'];
describe('Test Broken Links', () => {
it('Verify navigation across landing page links', () => {
cy.visit(baseUrl);
cy.get("a:not([href*='mailto:'])").each((linkElm) => {
const linkPath = linkElm.attr('href');
const shouldExclude = excludedLinks.reduce((p, c) => {
if (p || linkPath.includes(c)) {
return true;
}
return false;
}, false);
if (linkPath.length > 0 && !shouldExclude) {
cy.request(linkPath).then((res) => {
expect(res.status).to.eq(200);
});
}
});
});
});A couple of lines worth pointing out:
- I'm setting the
baseURLbased on my environment. - I have a list of
excludedLinksdue to some scraping edge cases. (LinkedIn, for example, returns a 999 when a bot visits a page) - The real meat: After I extract the
hrefattributes, I run through each and check the status with theexpectmethod.
From this, Cypress will run through each link and return results like so: